Notes:
- Make sure that environment variables are set as described in Tutorial Installation and HiFST Paths and Environment Variables.
- Make sure that the language models are downloaded and uncompressed into the
$DEMO/M/directory. - Make sure that the wordmaps are uncompressed in the
$DEMO/wmaps/directory - Make sure you're in the
$DEMOdirectory.
> cd $DEMO
Basic Translation Operations
The first demonstration exercise is to generate translations of integer-mapped Russian text using the translation grammar and English n-gram language model provided. HiFST is configured to generate one-best translation hypotheses as well as translation lattices.
The baseline configuration file is configs/CF.baseline, which also contains comments giving brief explanations of HiFST options. The following command will translate the first 2 lines in the Russian integer-mapped file RU/RU.set1.idx:
# Run HiFST
> mkdir log
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline &> log/log.baseline
The log file output can be viewed as:
> tail -n 11 log/log.baseline Fri Apr 3 12:48:16 2015: run.INF:loading LM=M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.withoptions.mmap Fri Apr 3 12:48:16 2015: run.INF:Stats for Sentence 1: local pruning, number of times=0 Fri Apr 3 12:48:16 2015: run.INF:End Sentence ****************************************************** Fri Apr 3 12:48:16 2015: run.INF:Writing lattice 1 to ... output/exp.baseline/LATS/1.fst.gz Fri Apr 3 12:48:16 2015: run.INF:Translation 1best is: 1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2 Fri Apr 3 12:48:16 2015: run.INF:=====Translate sentence 2:1 16055 3 102 5182 66 18 23602 12611 5 6522 2377 3431 3 98 52858 61 46 2140 4422 15871 25 67408 17658 26 1731 19663 4 2 Fri Apr 3 12:48:16 2015: run.INF:Stats for Sentence 2: local pruning, number of times=0 Fri Apr 3 12:48:22 2015: run.INF:End Sentence ****************************************************** Fri Apr 3 12:48:22 2015: run.INF:Writing lattice 2 to ... output/exp.baseline/LATS/2.fst.gz Fri Apr 3 12:48:22 2015: run.INF:Translation 1best is: 1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 4 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2 Fri Apr 3 12:48:22 2015: ~MainClass.INF:hifst.O2.bin ends!
The best scoring translation hypotheses are given in integer-mapped form, e.g. for the first Russian sentence, the best-scoring translation hypothesis is
run.INF:Translation 1best is: 1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2
Printing the 1-Best Hypotheses
The configuration file configs/CF.baseline instructs HiFST to write its 1-best translations to the output file output/exp.baseline/hyps (see the target.store=output/exp.baseline/hyps specification in the config file). The contents of this file should agree with the Translation 1best entries in the log file (compare these results to the entries in the log file, above):
> cat output/exp.baseline/hyps 1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2 1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 4 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2
The FST Archive (FAR) command line tools (in the OpenFst FAR extensions) can be used to load the English wordmap (wmaps/wmt13.en.wmap) and print the hypotheses in readable form:
> farcompilestrings --entry_type=line output/exp.baseline/hyps | farprintstrings --symbols=wmaps/wmt13.en.wmap <s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> <s> amendment , which would have led to the release of which is in prison , former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences . </s>
Note that loading the English wordmap can be time consuming due to its size. Ideally, in processing multiple translation hypotheses, the wordmap should be loaded only once, rather than once for each sentence.
Extracting the Best Translation from a Lattice
The configuration file also directs HiFST to write translation lattices to output/exp.baseline/LATS/?.fst.gz (see the hifst.lattice.store=output/exp.baseline/LATS/?.fst.gz specification in the config file). Note the use of the placeholder '?' in the argument .../LATS/?.fst.gz . The placeholder is replaced by the line number of sentence being translated, e.g. so that .../LATS/2.fst.gz is a weighted finite state transducer (WFST) containing translations of the second line in the source text file. Note also the use of the '.gz' extension: when this is provided, lattices are written as gzipped files.
OpenFst operations can be used to compute the shortest path through each of these output lattices, and the results should agree with the top-scoring hypotheses in the file output/exp.baseline/hyps and the log file:
> echo `zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fsttopsort | fstprint | awk '{print $3}'`
1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2
> echo `zcat output/exp.baseline/LATS/2.fst.gz | fstshortestpath | fsttopsort | fstprint | awk '{print $3}'`
1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 4 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2
The English wordmap can be supplied to fstprint to convert from integer mapped strings to English:
> echo `zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fsttopsort | fstprint --isymbols=wmaps/wmt13.en.wmap | awk '{print $3}'`
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
> echo `zcat output/exp.baseline/LATS/2.fst.gz | fstshortestpath | fsttopsort | fstprint --isymbols=wmaps/wmt13.en.wmap | awk '{print $3}'`
<s> amendment , which would have led to the release of which is in prison , former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences . </s>
For convenience, the HiFST printstring utility programme gathers all these operations into a single binary:
> printstrings.${TGTBINMK}.bin --range=1:2 --label-map=wmaps/wmt13.en.wmap --input=output/exp.baseline/LATS/?.fst.gz --semiring=lexstdarc
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> amendment , which would have led to the release of which is in prison , former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences . </s>
...
Note the use of the range=1:2 command line option, which specifies which fsts are to be processed, and also that wordmap file is loaded only once, which can speed operations. Note also that the output fsts are in the lexstdarc semiring, described later.
OpenFst ShortestPath Operations
The above OpenFst operations do the following:
zcatpipes the HiFST output lattice to the OpenFst Shortest Path tool which produces an FST containing only the shortest path in the lattice- the OpenFst Topological Sort operation renumbers the state IDs so that all arcs are links from lower to higher state IDs
- the OpenFst fstprint operation reads the English wordmap, for the arc input symbols, and traverses the input fst, writing each arc as it is encountered; TopSort ensures these arcs are written in the correct order
- the awk operation prints only the words on the arcs
- wrapping everything inside echo generates a single string
To see what is produced at the various steps in the pipeline:
Input lattice:
> zcat output/exp.baseline/LATS/1.fst.gz | fstinfo | head -6 fst type vector arc type tropical_LT_tropical input symbol table none output symbol table none # of states 656 # of arcs 1513
Shortest Path:
> zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fstprint 16 15 1 1 -2.68554688,-2.68554688 0 1 0 2 2 2.83719015,-2.34277344 2 1 23899 23899 10.2336502,0 3 2 6 6 1.83065951,0 4 3 425 425 4.19441986,0 5 4 3 3 -3.28652811,-5.1171875 6 5 48 48 3.01827216,0 7 6 1145 1145 4.64596272,0 8 7 25 25 1.83065951,0 9 8 4 4 0.548432946,-1.28222656 10 9 245 245 5.13327551,-0.48828125 11 10 3 3 0.961314559,0 12 11 103 103 4.64596272,0 13 12 20 20 0.961314559,0 14 13 135 135 1.43660688,-4.65039062 15 14 50 50 6.39422989,-2.88476562
Note that the paired weights are described in Lexicographic Semirings: Translation Grammar and Language Model Scores.
Topologically Sorted Shortest Path:
> zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fsttopsort | fstprint 1 1 1 1 -2.68554688,-2.68554688 1 2 50 50 6.39422989,-2.88476562 2 3 135 135 1.43660688,-4.65039062 3 4 20 20 0.961314559,0 4 5 103 103 4.64596272,0 5 6 3 3 0.961314559,0 6 7 245 245 5.13327551,-0.48828125 7 8 4 4 0.548432946,-1.28222656 8 9 25 25 1.83065951,0 9 10 1145 1145 4.64596272,0 10 11 48 48 3.01827216,0 11 12 3 3 -3.28652811,-5.1171875 12 13 425 425 4.19441986,0 13 14 6 6 1.83065951,0 14 15 23899 23899 10.2336502,0 15 16 2 2 2.83719015,-2.34277344 16
Toplogically Sorted Shortest Path, with English words replacing the arc input symbols
> zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fsttopsort | fstprint --isymbols=wmaps/wmt13.en.wmap --acceptor 0 1 <s> -2.68554688,-2.68554688 1 2 parliament 6.39422989,-2.88476562 2 3 does 1.43660688,-4.65039062 3 4 not 0.961314559,0 4 5 support 4.64596272,0 5 6 the 0.961314559,0 6 7 amendment 5.13327551,-0.48828125 7 8 , 0.548432946,-1.28222656 8 9 which 1.83065951,0 9 10 gives 4.64596272,0 10 11 you 3.01827216,0 11 12 the -3.28652811,-5.1171875 12 13 freedom 4.19441986,0 13 14 of 1.83065951,0 14 15 tymoshenko 10.2336502,0 15 16 </s> 2.83719015,-2.34277344 16
Extracting N-Best Translations from Lattices
The printstrings can also can print the top-N hypotheses, using the OpenFst Shortest Path operation, with its n-shortest path option:
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --nbest=10 --unique --input=output/exp.baseline/LATS/1.fst.gz
...
1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2
1 50 135 20 103 34 245 4 25 1145 48 3 425 6 23899 2
1 3 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2
1 50 311 20 103 3 245 4 25 1145 48 3 425 6 23899 2
1 50 135 20 103 3 245 4 25 1145 48 3 425 7 23899 2
1 50 135 20 103 3 245 4 25 1145 48 425 6 23899 2
1 50 135 20 103 3 245 4 25 1145 425 6 23899 2
1 50 135 20 103 3 245 4 25 1145 408 23899 2
1 50 135 20 103 3 245 4 25 1145 3 425 6 23899 2
1 50 135 20 103 3 245 4 25 1145 48 408 23899 2
...
With the English wordmap, printstrings will map the integer representation to English text:
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --nbest=10 --unique --input=output/exp.baseline/LATS/1.fst.gz --label-map=wmaps/wmt13.en.wmap
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support an amendment , which gives you the freedom of tymoshenko </s>
<s> the parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament did not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom to tymoshenko </s>
<s> parliament does not support the amendment , which gives you freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives free tymoshenko </s>
<s> parliament does not support the amendment , which gives the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you free tymoshenko </s>
...
It often happens that a translation hypothesis can be produced by multiple derivations (i.e. rule sequences), so the top scoring hypotheses need not be unique. For example, omitting the --unique shows repetitions among the top hypotheses:
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --nbest=10 --input=output/exp.baseline/LATS/1.fst.gz --label-map=wmaps/wmt13.en.wmap
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s>
...
Weight Vectors and Feature Vectors
HiFST computes a translation score S(e) for each hypothesis e by applying a weight vector P to a feature vector F(e). The relationship of feature vectors and scores at the hypothesis level is as follows:
- Suppose there are m language models, with weights s_1 ...,s_m .
- These weights are specified by the HiFST parameters
lm.featureweights=s_1,s_2,..,s_m
- These weights are specified by the HiFST parameters
- Suppose there are n-dimensional feature vectors for each rule in the translation grammar,
- The weights to be applied are specified by the HiFST parameters
grammar.featureweights=w_1,..,w_n
- The weights to be applied are specified by the HiFST parameters
- A feature weight vector is formed as P = [s_1 ... s_m w_1 ... w_n]
- A translation hypothesis e has a feature vector F(e) = [lm_1(e) ... lm_m(e) f_1(e) ... f_n(e)]
- lm_i(e): the i-th language model score for e
- f_j(e): j-th grammar feature (see Section 3.2.1, [deGispert2010])
- The score of translation hypothesis e can be found as S(e) = F(e) . P (dot product)
Applying Weight Vectors in Translation
As an example, the translation grammar G/rules.shallow.vecfea.gz has unweighted 11-dimensional (n=11) feature vectors associated with each rule:
> gzip -d -c G/rules.shallow.vecfea.gz | head -3 V 3 4 0.223527 0.116794 -1 -1 0 0 0 0 -1 1.268789 0.687159 V 3 4_3 3.333756 0.338107 -2 -1 0 0 0 0 -1 1.662178 3.363062 V 3 8 3.74095 3.279819 -1 -1 0 0 0 0 -1 3.741382 2.271445
We have run lattice MERT (Lattice MERT) to generate a parameter weight vector for this grammar with these features and the language model M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.withoptions.mmap
> P=1.0,0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136
Note that P is 12-dimensional: the weighting of the language model score is 1.0, and the weights applied to the grammar feature vectors are
GW=0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136
There are (at least) three different ways to apply the feature weights to the unweighted feature vectors in the grammar:
Feature weights can be applied to the grammar, prior to translation:
> mkdir -p tmp/
> gzip -dc G/rules.shallow.vecfea.gz | ./scripts/weightgrammar -w=$GW | gzip > tmp/rules.shallow.RS.gz
> hifst.${TGTBINMK}.bin --config=configs/CF.nogrammar --grammar.load=tmp/rules.shallow.RS.gz --target.store=tmp/hyps.1
Feature weights can be applied in translation, using the options --grammar.featureweights=$GW and --lm.featureweights=1.0.
HiFST loads the grammar with unweighted feature vectors, and applies the feature weights on-the-fly:
> hifst.${TGTBINMK}.bin --config=configs/CF.nogrammar --grammar.load=G/rules.shallow.vecfea.gz --grammar.featureweights=$GW --lm.featureweights=1.0 --target.store=tmp/hyps.2
Feature weights can be applied in translation, using the --featureweight=$P option.
HiFST loads the grammar with unweighted feature vectors, and applies the feature weights on-the-fly. HiFST automatically determines which elements of P should be applied to the language model scores, and which should be applied to the unweighted feature vectors in the translation grammar:
> hifst.${TGTBINMK}.bin --featureweights=$P --config=configs/CF.nogrammar --target.store=tmp/hyps.3 --grammar.load=G/rules.shallow.vecfea.gz
These three alternative methods should yield identical results (to verify, compare tmp/hyps.[123]). Note that the last alternative is useful for iterative parameter estimation procedures, such as MERT.
Lexicographic Semirings: Translation Grammar and Language Model Scores
HiFST follows the formalism in which rule probabilities are represented as arc weights (see Section 2 of [deGispert2010]). A rule with probability p is represented as a negative log probability, i.e.
X -> < A , B > / - log(p)
with n-gram language model scores encoded similarly, as costs -log P(w|h) for word w with LM history h. Costs are accumulated at the path level, so that the shortest path through the output FSA accepts the highest scoring hypothesis under the translation grammar and the language model (with feature weights applied as described in Weight Vectors and Feature Vectors). With this mapping of scores to costs, the OpenFst ShortestPath can be used to extract the best scoring hypothesis under the tropical semiring.
HiFST uses a lexicographic semiring of two tropical weights [Roark2011]. For example,
> zcat output/exp.baseline/LATS/1.fst.gz | fstinfo | head -2 fst type vector arc type tropical_LT_tropical > zcat output/exp.baseline/LATS/1.fst.gz | fstprint | head -n 10 0 1 1 1 -2.68554688,-2.68554688 1 4 170 170 11.4819975,4.25097656 1 3 50 50 6.39422989,-2.88476562 1 2 3 3 1.87243128,-2.70800781 1 197 50 50 3.70087051,-5.578125 1 196 3 3 -0.820928097,-5.40136719 1 456 50 50 7.04462051,-2.234375 1 455 3 3 1.72790003,-2.85253906 1 195 50 50 6.01825333,-3.26074219 1 81 170 170 5.89898968,-1.33203125
The arc type of tropical_LT_tropical indicates that the lexicographic semiring is a pair of tropical weights. As produced by HiFST, the pairs of tropical weights are (G+M, G), where the first weight (G+M) contains the complete translation score (the translation grammar score G + the language model score M), and the second weight G only contains the translation grammar score. The advantage of using the lexicographic semiring in this way is that the language model scores can be removed and reapplied very efficiently (see Language Model Rescoring).
In the above example, scores are distributed over the arcs in the FST. The OpenFst Push operation can be used to accumulate weights at the path level within the shortest path fst:
> zcat output/exp.baseline/LATS/1.fst.gz | fstshortestpath | fsttopsort | fstpush --push_weights --to_final | fstprint --isymbols=wmaps/wmt13.en.wmap --acceptor 0 1 <s> 1 2 parliament 2 3 does 3 4 not 4 5 support 5 6 the 6 7 amendment 7 8 , 8 9 which 9 10 gives 10 11 you 11 12 the 12 13 freedom 13 14 of 14 15 tymoshenko 15 16 </s> 16 42.6998749,-19.4511719
In this example, (G+M, G) is (42.6998749,-19.4511719). The first component, 42.6998749, contains the sum of the translation grammar scores and the language model - this is the score assigned to the hypotheses by the decoder. The second component, -19.4511719, is the translation grammar score alone, i.e. contains the score assigned to the hypotheses under the translation grammar without the language model (see Section 5.1 of [Allauzen2014]). The lexicographic semiring is such that these scores are computed correctly at the path level:
- The cost of the shortest path found by ShortestPath is that of the best hypothesis under the sum of the translation grammar score and the language model score(s)
- In the lexicographic semiring, when the path weight is pushed to the final state:
- the first weight component is the correct combined translation grammar and language model score
- the second weight component is the best grammar score over all possible derivations that could have generated this hypothesis
The HiFST utility printstrings also works with the lexicographic semiring, and gives the same results as using the ShortestPath and Push operations:
> printstrings.${TGTBINMK}.bin --input=output/exp.baseline/LATS/1.fst.gz --label-map=wmaps/wmt13.en.wmap --semiring=lexstdarc --weight
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 42.6999,-19.4512 ...
Printing the top 5 hypotheses shows that hypotheses are scored and ranked under the combined grammar and language model score G+M:
> printstrings.${TGTBINMK}.bin --input=output/exp.baseline/LATS/1.fst.gz --label-map=wmaps/wmt13.en.wmap --semiring=lexstdarc --weight --nbest=5 --unique
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 42.7003,-19.4512
<s> parliament does not support an amendment , which gives you the freedom of tymoshenko </s> 44.2802,-20.8945
<s> the parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 45.4819,-19.9385
<s> parliament did not support the amendment , which gives you the freedom of tymoshenko </s> 45.7096,-15.5635
<s> parliament does not support the amendment , which gives you the freedom to tymoshenko </s> 45.8136,-19.0361
Admissible Pruning
HiFST can prune translation lattices prior to saving them to disk; this is most often a practical necessity. Pruning is done using the OpenFst Prune operation. Pruning in this case is admissible, since it is performed after grammar and language model scores have been completely applied. Low-scoring hypotheses are discarded, but no search errors are introduced by this pruning. This is also referred to as top-level pruning, as described in detail in Section 2.2.2, [deGispert2010].
Top-level pruning is controlled by the --hifst.prune option. In the previous examples, --hifst.prune was set to 9. If we use the default (3.40282347e+38), then the output lattice size becomes very large. For example, compare lattices in exp1/ generated with prune=9 vs. unpruned lattices in exp2/:
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline.outputnoprune &> log/log.baseline.outputnoprune
> du -sh output/exp.baseline/LATS/1.fst.gz output/exp.baseline.outputnoprune/LATS/1.fst.gz
12K output/exp.baseline/LATS/1.fst.gz
1.1M output/exp.baseline.outputnoprune/LATS/1.fst.gz
> du -sh output/exp.baseline/LATS/2.fst.gz output/exp.baseline.outputnoprune/LATS/2.fst.gz
148K output/exp.baseline/LATS/2.fst.gz
16M output/exp.baseline.outputnoprune/LATS/2.fst.gz
The OpenFst fstinfo command also indicates much larger outputs:
> zcat output/exp.baseline/LATS/2.fst.gz | fstinfo | grep \# | head -2 # of states 5833 # of arcs 22845 > zcat output/exp.baseline.outputnoprune/LATS/2.fst.gz | fstinfo | grep \# | head -2 # of states 172843 # of arcs 2481006
The unpruned lattices are much bigger, and contain many translation hypotheses, although the top scoring hypotheses should be unchanged by this form of pruning, as is the case in this example:
> head output/exp.baseline/hyps output/exp.baseline.outputnoprune/hyps ==> output/exp.baseline/hyps <== 1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2 1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 4 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2 ==> output/exp.baseline.outputnoprune/hyps <== 1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2 1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 4 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2
Inadmissible Pruning
Inadmissible pruning, or local pruning, controls processing speed and memory use during translation. Only enough details are reviewed here to describe how HiFST performs pruning in search; for a detailed discussion of local pruning and pruning in search, see Section 2.2.2 of [deGispert2010].
Given a translation grammar and a source language sentence, HiFST first constructs a Recursive Transition Network (RTN) representing the translation hypotheses [Iglesias2009a, Iglesias2011]. This is done as part of a modified CYK algorithm used to parse the source sentence under the translation grammar. The RTN is then expanded to an equivalent WFSA via the OpenFst Replace operation. This WFSA contains the translation hypotheses along with their scores under the translation grammar. We refer to this as the `top-level' WFSA, because it is associated with the top-most cell in the CYK grid. This top-level WFSA can be pruned after composition with the language model, as described in the discussion of Admissible Pruning. We refer to this as exact search or exact translation. In exact translation, no translation hypotheses are discarded prior to applying the complete grammar and language model scores.
Exact translation can be done under some combinations of translation grammars, language models, and language pairs. In particular, the Shallow-N Translation Grammars were designed for exact search. However attempting exact translation under many translation grammars would cause either the Replace operation or the subsequent language model composition to become computationally intractable. We therefore have developed a pruning strategy that prunes the RTN during its construction.
The RTN created by HiFST can be described as follows:
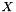 is the set of non-terminals in the translation grammar, with
is the set of non-terminals in the translation grammar, with 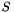 as the root
as the root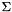 is the target language vocabulary, i.e. the terminals in the target language
is the target language vocabulary, i.e. the terminals in the target language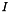 is the length of the source sentence
is the length of the source sentence 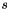 , i.e.
, i.e. 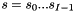
- A new set of non-terminals is defined as
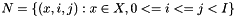
- Note that
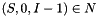
- Note that
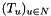 , is a family of WFSAs with input alphabet
, is a family of WFSAs with input alphabet 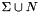
- Each
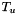 with
with 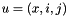 , is a WFSA that describes all applications of translation rules with left-hand side non-terminal
, is a WFSA that describes all applications of translation rules with left-hand side non-terminal 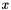 that span the substring
that span the substring 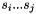
- is associated with the CYK grid cell associated with source space
![$[i,j]$](form_14.png) and headed by non-terminal
and headed by non-terminal
- Each
- The top-level RTN is defined as
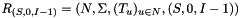 .
.- The root symbol of this RTN is
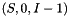 .
. - The WFSA
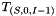 represents all applications of translation rules that span the entire sentence and are rooted with non-terminal .
represents all applications of translation rules that span the entire sentence and are rooted with non-terminal .
- The root symbol of this RTN is
Exact translation is achieved if every is complete (i.e. if no pruning is done) prior to the OpenFst Replace operation on the RTN 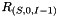 . This produces a WFSA that contains all translations that can be produced under the translation grammar.
. This produces a WFSA that contains all translations that can be produced under the translation grammar.
The RTN pruning strategy relies on noting that each of the WFSAs 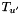 ,
, 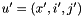 , also defines an RTN
, also defines an RTN 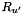 , as follows:
, as follows:
- Define a subset of non-terminals
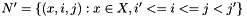 , i.e.
, i.e. 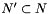
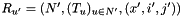
- The root symbol of this RTN is
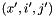
- The root symbol of this RTN is
The Replace operation can be applied to the RTNs to produce an WFSA containing all translations of the source string 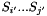 using derivations rooted in the non-terminal
using derivations rooted in the non-terminal 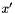 . This WFSA can be pruned and used in place of the original .
. This WFSA can be pruned and used in place of the original .
Because of the possibility of search errors we refer to this as 'local pruning' or inadmissible pruning. There is the possibility that pruning any of the may possibly cause some good translations to be discarded. For this reason it is important to tune the pruning strategy for the translation grammar and language model. Once pruning has been set, the benefits are
- faster creation of the top-level WFSA via the Replace operation
- faster composition of the translation WFSA with the language model
- less memory used in RTN construction and language model composition
Local pruning should be done under the combined grammar and the language model scores, rather than under the translation grammar scores alone alone. However, the LM used in local pruning can be relatively weak. For example, if the main language model used in translation is a 4-gram, perhaps a 3-gram or even a bigram language model could be used in local pruning. Using a smaller language model will make pruning faster, as will an efficient scheme to remove the scores of the language models used in pruning. The lexicographic semiring, see Lexicographic Semirings: Translation Grammar and Language Model Scores, makes this last operation easy.
Local Pruning Algorithm
HiFST monitors the size of the during translation. Any of these automata that exceed specified thresholds are converted to WFSAs and pruned. Subsequent expansion of the RTN is then done with respect to the pruned versions of .
Local pruning is controlled via the following HiFST parameters:
hifst.localprune.enable=yes # must be set to activate local pruning hifst.localprune.conditions=NT_1,span_1,size_1,threshold_1,...,NT_N,span_N,size_N,threshold_N hifst.localprune.lm.load=lm_1,...lm_K hifst.localprune.lm.featureweights=scale_1,...,scale_K hifst.localprune.lm.wps=wp_1,...,wp_K
In the above, an arbitrary number N of tuples (NT_n, span_n, size_n, threshold_n) can be provided; similarly, an arbitrary number K of language model parameters (lm_k, scale_k, wp_k) can also be used in pruning.
Pruning is applied during construction of the RTN, as follows:
- If any satisfies the following conditions for any parameter set (
NT_n,span_n,size_n,threshold_n), n=1,...,N- NT_n = X
- span_n <= j-i
- size_n <= number of states of , computed via OpenFst
NumStates()
- then is pruned as follows:
- OpenFst Replace converts
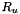 to a WFSA
to a WFSA - RmEpsilon,Deteminize, and Minimize generate a compacted WFSA
- Composition with K language model(s) WFSAs
- The parameters (
lm_k,scale_k,wp_k) specify the language models, language model scale factors, and word penalties to be applied
- The parameters (
- OpenFst Prune is applied with threshold
threshold_n - Language model scores are removed by copying component weights in the lexicographic semiring, see Lexicographic Semirings: Translation Grammar and Language Model Scores
- RmEpsilon,Deteminize, and Minimize, yielding a pruned WFSA with only translation scores and target language symbols
- OpenFst Replace converts
- The pruned version of is then used in place of the original version in the RTN
Effect on Speed, Memory, Scores
Pruning in search is particularly important when running HiFST with grammars that are more powerful than the shallow grammar used in these examples. However, we can still see speed and memory use improvements through local pruning, particularly with long sentences.
First, pick some long source language sentences to translate:
> awk 'NF>80' RU/RU.tune.idx > tmp/RU.long.idx # should be 3 sentences
Translate these long sentences under the baseline Shallow-1 grammar; note this will overwrite the output in output/exp.baseline/
> (time hifst.${TGTBINMK}.bin --config=configs/CF.baseline --range=1:3 --source.load=tmp/RU.long.idx ) &> log/log.long
The maximum memory use is approximately 2.5GB and translation takes approximately 1m30s. (The resource consumption may vary depending on your hardware, we provide these numbers to illustrate the effect of local pruning.)
If translation is performed with the same grammar and language model, but with aggressive local pruning,
> (time hifst.${TGTBINMK}.bin --config=configs/CF.baseline.localprune) &> log/log.baseline.localprune
then the memory consumption is reduced to under 2.2GB and the processing time to approximately 40s. Note that local pruning does not have as great an effect on translation under the Shallow-1 grammar as it would with e.g. a full Hiero grammar.
Inspecting the log file indicates that local pruning was applied extensively in translation:
> grep pruning log/log.baseline.localprune Mon Apr 6 19:06:46 2015: run.INF:Stats for Sentence 1: local pruning, number of times=266 Mon Apr 6 19:07:01 2015: run.INF:Stats for Sentence 2: local pruning, number of times=279 Mon Apr 6 19:07:16 2015: run.INF:Stats for Sentence 3: local pruning, number of times=154
Pruning is aggressive enough here that the translations are affected:
> printstrings.${TGTBINMK}.bin -w --semiring=lexstdarc -m wmaps/wmt13.en.wmap --input=output/exp.baseline/LATS/1.fst.gz
<s> the decline in economic activity caused , until november , the permanent rise in unemployment in the state , according to the national institute of statistics and geography , in the first three quarters was recorded accelerated growth in unemployment , from january to march 55.053 resident sinaloa were unemployed , with the share of per cent of the economically active population , in the second quarter , the share rose to percent from july to september , she continued to rise to percent share , if calculated per number of people is more than unemployed people in sinaloa , the 18.969 people more than in the first half . </s> 471.123,2.46484
> printstrings.${TGTBINMK}.bin -w --semiring=lexstdarc -m wmaps/wmt13.en.wmap --input=output/exp.baseline.localprune/LATS/1.fst.gz
<s> the decline in economic activity caused , until november , the permanent rise in unemployment in the state , according to the national institute of statistics and geography , in the first three quarters was recorded accelerated growth in unemployment , from january to march 55.053 resident sinaloa were unemployed , with the share of per cent of the economically active population , in the second quarter share rose to percent from july to september , she continued to rise to percent stake , which is recalculated the number of people is more than unemployed people in sinaloa , the 18.969 people more than in the first half . </s> 472.86,3.74023
The best hypothesis generated under the baseline system without local pruning has a combined grammar and language model score of 471.123. This hypothesis does not survive more aggressive local pruning under these parameters , where the best hypothesis has a higher combined score of 472.86.
Language Model Rescoring
As discussed above, HiFST uses a lexicographic semiring (Lexicographic Semirings: Translation Grammar and Language Model Scores, [Roark2011]) of two tropical weights. In each arc of a lattice generated by HiFST, the first weight (G+M) contains the correct score (translation grammar score + language model score). The second weight G only contains the translation grammar score. An example is repeated here:
# re-run the translation baseline
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline &> log/log.baseline
> zcat output/exp.baseline/LATS/1.fst.gz | fsttopsort | fstprint | head -n 10
0 1 1 1 -2.68554688,-2.68554688
1 319 170 170 11.4819975,4.25097656
1 118 50 50 6.39422989,-2.88476562
1 104 3 3 1.87243128,-2.70800781
1 91 50 50 3.70087051,-5.578125
1 87 3 3 -0.820928097,-5.40136719
1 65 50 50 7.04462051,-2.234375
1 62 3 3 1.72790003,-2.85253906
1 47 50 50 6.01825333,-3.26074219
1 43 170 170 5.89898968,-1.33203125
The advantage of using the lexicographic semiring to represent (G+M,G) weights is that the language model score can be removed very efficiently: the second field is simply copied over the first field. HiFST binaries do this mapping internally with an OpenFst fstmap operation. The result is a WFSA whose weights contain only the translation grammar scores. The lexmap tool can be used to do this mapping, as follows, yielding lexicographic weights (G,G):
> zcat output/exp.baseline/LATS/1.fst.gz | lexmap.${TGTBINMK}.bin | fsttopsort | fstprint | head -n 10
0 1 1 1 -2.68554688,-2.68554688
1 319 170 170 4.25097656,4.25097656
1 118 50 50 -2.88476562,-2.88476562
1 104 3 3 -2.70800781,-2.70800781
1 91 50 50 -5.578125,-5.578125
1 87 3 3 -5.40136719,-5.40136719
1 65 50 50 -2.234375,-2.234375
1 62 3 3 -2.85253906,-2.85253906
1 47 50 50 -3.26074219,-3.26074219
1 43 170 170 -1.33203125,-1.33203125
Using this facility to remove language model scores, the HiFST applylm tool can be used to rescore lattices under a different language model than was used in first-pass translation. Operations are as follows:
- A lattice with lexicographic
(G+M,G)weights is loaded - Weights are converted to
(G,G)via fstmap - The new language model(s) are applied via composition under the lexicographic semiring, with optional scale factors and word insertion penalties. The new WFSAs weights are of the form
(G+M2,G), whereM2are the new language model weights. - The reweighted WFSA is written to disk, with either lexicographic or standard tropical weights
The following example uses applylm to rescore lattices generated with almost no pruning (output/exp.baseline.outputnoprune/LATS). Rescoring uses the same 4-gram language model originally used to generate the lattice, but with a different scale factor (lm.scale=0.9).
> applylm.${TGTBINMK}.bin --config=configs/CF.baseline.outputnoprune.lmrescore &> log/log.lmrescore
For the second sentence, the original 1-best hypothesis was:
> zcat output/exp.baseline.outputnoprune/LATS/2.fst.gz | printstrings.${TGTBINMK}.bin --semiring=lexstdarc -m wmaps/wmt13.en.wmap -w 2>/dev/null
<s> amendment , which would have led to the release of which is in prison , former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences . </s> 101.582,-37.5605
Rescoring yields a slightly different 1-best:
> zcat output/exp.baseline.lmrescore/LATS/2.fst.gz | printstrings.${TGTBINMK}.bin --semiring=lexstdarc -m wmaps/wmt13.en.wmap -w 2>/dev/null
<s> amendment , which would have led to the release of which is in jail of former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences . </s> 87.5249,-39.5508
Note the load.deletelmcost option in the configuration file, which instructs the tool to subtract old lm scores first. If the scaling is not changed, both lattices should be identical
(`applylm.${TGTBINMK}.bin --config=configs/CF.baseline.outputnoprune.lmrescore --lm.featureweights=1`).
Multithreading
Note that the timing results here are illustrative only.
HiFST uses Boost.Thread to enable multithreading. This is disabled by default, but can enabled using the flag --nthreads=N . If set, each source language sentence is translated simultaneously on its own thread (trimmed to the number of CPUs available). The translation grammar and language model are kept in shared memory.
To see the effects of multithreading on speed and memory use, the baseline configuration is run over the first twenty sentences without multithreading:
> time hifst.${TGTBINMK}.bin --config=configs/CF.baseline --range=1:20
Processing time is 105 seconds and maximum memory use is about 2GB. In the same decoder configuration but with 2 threads
> time hifst.${TGTBINMK}.bin --config=configs/CF.baseline --range=1:20 --nthreads=2
processing time is reduced to 60 seconds with maximum memory use of about 2.5GB.
In these examples, both the LM and translation grammar are relatively small, and so there is not a great deal of gain from keeping them in shared memory. But in larger tasks, multithreading can be a significant advantage.
Lattice Minimum Bayes Risk Decoding
For a detailed discussion of LMBR, see Chapters 7 and 8 in [BlackwoodPhD].
LMBR is a decoding procedure, based on the following:
- Evidence space: a lattice (WFSA) containing weighted translations produced by the SMT system.
- N-gram posterior distributions, with pathwise posteriors, are extracted from this WFSA.
- The hypotheses space: an unweighted lattice (FSA) containing hypotheses to be rescored.
The following steps are carried out in LMBR decoding:
- The evidence space is normalised after applying a grammar scale factor (
--alpha=). Scaling is done by the OpenFst Push towards final states, and setting the final state probability to 1.0. - N-grams are extracted from the hypothesis space.
- N-gram path-posterior probabilities are computed over the evidence space using a modified Forward procedure (see Blackwood2010)
- Cyclic WFSAs are built to represent posterior probability distribution of each n-gram order and compose with the original hypotheses space. A word insertion penalty (
--wps=) is also included in the costs of the cyclic WFSAs. - Risk is computed through a sequence of compositions.
- The result for LMBR decoding is a WFSA; each weighted path represents a hypothesis and its risk.
The weighted hypothesis space can be save as a WFSA, or the minimum risk hypothesis can be generated via the OpenFst ShortestPath operation.
The following example applies LMBR decoding to the baseline lattices
> lmbr.${TGTBINMK}.bin --config=configs/CF.baseline.lmbr &> log/log.baseline.lmbr
The LMBR output hyppthesis file keeps the scale factor, word penalty, and sentence id at the start of the file; the hypothesis follows the colon
> cat output/exp.baseline.lmbr/HYPS/0.40_0.02.hyp 0.4 0.02 1:1 50 135 20 103 3 245 4 25 1145 48 3 425 6 23899 2 0.4 0.02 2:1 245 4 25 35 23 1028 7 3 2295 6 25 12 9 2666 6 972 1052 564 4 51 1284 317 3 312 734 6 3 3423 7 4922 2057 14 119 3570 5 2
LMBR can be optimised by tuning the grammar scale factor and word insertion penalty. Once lattices are loaded into memory and n-grams are extracted (steps 1 - 5), rescoring is fast enough that it is practical and efficient to perform a grid search over a range of parameter values (see config file).
Hypotheses are written to different files, with names based on parameter values (e.g. as --writeonebest=output/exp.baseline.lmbr/HYPS/%alpha%_%wps%%.hyp ). The best set of values can be selected based on BLEU score, after mapping each integer mapped output back to words, detokenizing, and scoring on against references.
LMBR relies on a unigram precision (p) and precision ratio (r) that are computed over a development set, e.g. with verbose logs of a BLEU scorer such as NIST mteval1. The script $HiFSTROOT/scripts/lmbr/compute-testset-precisions.pl is included for this purpose.
If the option --preprune= is specified, the evidence space is pruned prior to computing posterior probabilities (i.e. pruning is done at threshold 7 in this example). If this option is not defined, the full evidence space will be passed through.
MERT (Features Only)
This section describes how to generate N-Best lists of features for use with MERT [Och 2003].
The following sequence of operations will generate hypotheses and feature vectors that can be used by MERT. We use N-Best lists of depth N = 100, set by the prunereferenceshortestpath= option in configs/CF.mert.alilats.nbest. For this tutorial, the configuration files specify multithreading, and N-Best lists will be generated only for the first 2 sentences in RU/RU.tune.idx.
> M=2
# Step 1. Generate hyps
> hifst.${TGTBINMK}.bin --config=configs/CF.mert.hyps --range=1:$M &> log/log.mert.hyps
# Step 2. Generate alignment lats
> hifst.${TGTBINMK}.bin --config=configs/CF.mert.alilats.nbest --range=1:$M &> log/log.mert.alilats.nbest
# Step 3. Generate feature vectors
> alilats2splats.${TGTBINMK}.bin --config=configs/CF.mert.vecfea.nbest --range=1:$M &> log/log.mert.nbest
The process takes the following as its input:
RU/RU.tune.idx– tuning set source language sentencesG/rules.shallow.vecfea.gz– translation grammar, with unweighted feature vectorsM/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap– target language model- Initial feature weights for the language model and translation grammar (see
configs/CF.mert.hypsand Applying Weight Vectors in Translation)- P=1.0,0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136
The output is written to two linked sets of files, for m=1,...,$M
output/exp.mert/nbest/VECFEA/$m.nbest.gz– word hypothesesoutput/exp.mert/nbest/VECFEA/$m.vecfea.gz– unweighted feature vectors
The output files contain 1) the top N hypotheses for each source sentence and 2) the corresponding unweighted feature vector obtained from the best derivation of each of those hypotheses:
> zcat output/exp.mert/nbest/VECFEA/1.nbest.gz | head -2 <s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.0904 <s> the parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.1757 > zcat output/exp.mert/nbest/VECFEA/1.vecfea.gz | head -2 62.5442 10.8672 8.3936 -16.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 16.3076 40.5293 63.1159 12.8613 8.7959 -17.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 17.0010 43.9482
As a sanity check, computing the inner product between the vector $P and the first unweighted feature vector yields the following score
43.09045369 = $P . [62.5442 10.8672 8.3936 -16.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 16.3076 40.5293]
which agrees with the score assigned to the top hypotheses by the decoder:
> printstrings.${TGTBINMK}.bin --input=output/exp.mert/LATS/1.fst.gz --weight --semiring=lexstdarc --label-map=wmaps/wmt13.en.wmap
...
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.093,-19.4512
...
Note that there can be minor numerical differences in the scores of the best derivations and the score found in the initial decoding, as the above example shows.
The three steps to generating the n-best hypotheses and unweighted feature vectors are described next.
Step 1. Hypotheses for MERT
- Input:
RU/RU.tune.idx– tuning set source language sentencesG/rules.shallow.vecfea.gz– translation grammarM/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap– target language model- language model and translation grammar feature weights (see
configs/CF.mert.hyps)
- Output:
output/exp.mert/LATS/?.fst.gz– word lattices (WFSAs), determinized and minimized
This step runs HiFST in the usual way to generate a set of translation hypotheses which will be used in MERT.
> hifst.${TGTBINMK}.bin --config=configs/CF.mert.hyps --range=1:$M &> log/log.mert.hyps
In this configuration, the grammar feature weights and the language model feature weights are applied on-the-fly to the grammar and language model as they are loaded. This allows feature vector weights to be changed at each iteration of MERT. This behaviour is specified through the following options in the CF.mert.hyps file, where we use the parameters from the baseline system:
[lm] load=M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap featureweights=1.0 # Note that for only one language model, this parameter will always be set to 1. # If there are multiple language models, the language model weights will be updated # after each iteration of MERT [grammar] load=G/rules.shallow.vecfea.gz featureweights=0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136 # Note that this parameter vector should be updated after each iteration of MERT # Updated versions can be provided via command line arguments
The translation grammar has its rules with unweighted feature vectors:
> zcat G/rules.shallow.vecfea.gz | head -n 3 V 3 4 0.223527 0.116794 -1 -1 0 0 0 0 -1 1.268789 0.687159 V 3 4_3 3.333756 0.338107 -2 -1 0 0 0 0 -1 1.662178 3.363062 V 3 8 3.74095 3.279819 -1 -1 0 0 0 0 -1 3.741382 2.271445
The output lattices in output/exp.mert/LATS are acceptors containing word hypotheses, with weights in the form of the lexicographic semiring as described earlier.
> zcat output/exp.mert/LATS/1.fst.gz | fstinfo | head -n 2
fst type vector
arc type tropical_LT_tropical
> zcat output/exp.mert/LATS/1.fst.gz | printstrings.${TGTBINMK}.bin --semiring=lexstdarc -m wmaps/wmt13.en.wmap -w 2>/dev/null
<s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.093,-19.4512
Step 2. Guided Translation / Forced Alignment
- Input:
RU/RU.tune.idx– tuning set source language sentencesG/rules.shallow.gz– translation grammarM/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap– target language modeloutput/exp.mert/LATS/?.fst.gz– word lattices (WFSAs), determinized and minimized (from Step 1. Hypotheses for MERT)
- Output:
output/exp.mert/nbest/ALILATS/?.fst.gz– transducers mapping derivations to translations (e.g. Fig. 7, [deGispert2010])
Alignment is the task of finding the derivations (sequences of rules) that can produce a given translation. HiFST performs alignment via constrained translation (see Section 2.3, [deGispert2010] for a detailed description). This command runs HiFST in alignment mode:
> hifst.${TGTBINMK}.bin --config=configs/CF.mert.alilats.nbest --range=1:$M &> log/log.mert.alilats.nbest
In alignment mode, HiFST constructs substring acceptors (see Fig. 8, [deGispert2010]). These are constructed for each sentence as follows:
- the lattice from Step 1 is loaded by HiFST
- an N-Best list in the form of a WFSA is extracted (using
fstshortestpath) under the grammar and language model score from Step 1 - weights are removed from N-Best WFSA
- the WFSA is transformed to a substring acceptor
The translation grammar is applied in the usual way, but the translations are intersected with the substring acceptors so that only translations in the N-Best lists are retained. This generates every possible derivation of each N-Best list entry.
This behaviour is specified by the following config file parameters:
[referencefilter] load=output/exp.mert/LATS/?.fst.gz # perform alignment against these reference lattices containing initial hypotheses prunereferenceshortestpath=100 # on loading the reference lattices, transform them to n-best lists prior to alignment. # uses fstshortestpath
Note that application of the substring acceptors is very efficient; and this alignment step should be much faster than the translation operation of Step 1. The alignment lattices (referred to as ALILATS) map rule sequences (derivations) to translation hypotheses. Weights remain in lexicographic semiring form.
> zcat output/exp.mert/nbest/ALILATS/1.fst.gz | fstinfo | head -n 2 fst type vector arc type tropical_LT_tropical
Individual rules are identified by their line number in the translation grammar file. A rule map can be created as
> zcat G/rules.shallow.gz | awk 'BEGIN{print "0\t0"}{printf "%s-><%s,%s>\t%d\n", $1, $2, $3, NR}' > tmp/rules.shallow.map
> head -5 tmp/rules.shallow.map
0 0
V-><3,4> 1
V-><3,4_3> 2
V-><3,8> 3
V-><3,10> 4
The ALILATS transducers are not determinised: they contain every possible derivation for each N-Best list entry. The following example prints some of the alternative derivations of the top-scoring hypothesis:
# create a simple, unweighted acceptor for the top-scoring hypothesis
> zcat output/exp.mert/LATS/1.fst.gz | fstshortestpath | fstmap --map_type=rmweight > tmp/1.fst
# print the two best derivations for the top-scoring hypothesis
> zcat output/exp.mert/nbest/ALILATS/1.fst.gz | fstcompose - tmp/1.fst | fstproject | printstrings.${TGTBINMK}.bin --nbest=2 --semiring=lexstdarc -m tmp/rules.shallow.map
S-><1,1> V-><3526,50> X-><V,V> S-><S_X,S_X> V-><28847,245> X-><10_1278_V,135_20_103_3_V> S-><S_X,S_X> V-><3_64570,4_25_1145_48> X-><V,V> S-><S_X,S_X> V-><1857,3_425_6> X-><V_7786,V_23899> S-><S_X,S_X> X-><2,</s>> S-><S_X,S_X>
S-><1,1> V-><3526,50> X-><V,V> S-><S_X,S_X> V-><28847,245> X-><10_1278_V,135_20_103_3_V> S-><S_X,S_X> V-><3_64570,4_25_1145_48> X-><V,V> S-><S_X,S_X> V-><1857,3_425_6> X-><V,V> S-><S_X,S_X> V-><7786,23899> X-><V,V> S-><S_X,S_X> X-><2,</s>> S-><S_X,S_X>
The order of the rules in these rule sequences correspond to HiFST's bottom-up (left-to-right) CYK grid structure. Rule IDs are added as input symbols to the component WFSTs in the RTN following the translation rule (with its non-terminals). This leads to the bottom-up ordering after Replacement.
Step 3. Hypotheses with Unweighted Feature Vectors
- Input:
G/rules.shallow.vecfea.gz– translation grammar, rules with (unweighted) feature vectorsoutput/exp.mert/nbest/ALILATS/?.fst.gz– transducers mapping derivations to translations, for n-best entries (from Step 2. Guided Translation / Forced Alignment)- language model and translation grammar feature weights (see
configs/CF.mert.vecfea.nbest)
- Output:
output/exp.mert/lats/VECFEA/?.nbest.gz– N-best hypothesesoutput/exp.mert/lats/VECFEA/?.vecfea.gz– N-best unweighted features
The alilats2splats tool transforms ALILATS alignment lattices (transducers) to sparse vector weight lattices; see Section 2.3.1, [deGispert2010] for a detailed explanation.
> alilats2splats.${TGTBINMK}.bin --config=configs/CF.mert.vecfea.nbest --range=1:$M &> log/log.mert.nbest
The output is written to two sets of files:
N-best lists:
> zcat -f output/exp.mert/nbest/VECFEA/1.nbest.gz | head -n 2 <s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.0904 <s> the parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.1757
Vecfea files:
> zcat -f output/exp.mert/nbest/VECFEA/1.vecfea | head -n 2 62.5442 10.8672 8.3936 -16.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 16.3076 40.5293 63.1159 12.8613 8.7959 -17.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 17.0010 43.9482
- Line
nin the nbest list is the `n-th' translation hypotheses, as ranked under the combined grammar and language model scores. - Line
nin the vecfea file is a vector obtained by summing the unweighted feature vectors of each rule in the best derivation of then-thhypothesis
The alilats2splats tool works as follows:
- The translation grammar with (unweighted) feature vectors is loaded
- a Rule Flower acceptor, R, is created. This is an acceptor for rule sequences that applies vector weights (specifically, the feature vector for each rule). See Fig. 9 of [deGispert2010] for an example and an explanation.
- For each source sentence, the ALILATS derivation-to-translation transducer from Step 2 is loaded, and its weights are removed. Call this T_u
- The unweighted derivations-to-translation trandsducer T_u is composed with the Rule Flower acceptor R under the tropical sparse tuple weight semiring with the same feature vectors as are used to generate the translation.
- The feature vector for the best scoring derivation for every translation is found as Determinise(Project_output(R o T_u) )
- Language model scores M_1, ..., M_m are applied (again in the tropical sparse tuple weight semiring, so that each score ends up in a separate element in the vector) as Determinise(Project_output(R o T_u) ) o M_1 o ... o M_m
Writing of N-Best lists and features is controlled by the sparseweightvectorlattice options storenbestfile and storefeaturefile:
[sparseweightvectorlattice] loadalilats=output/exp.mert/nbest/ALILATS/?.fst.gz storenbestfile=output/exp.mert/nbest/VECFEA/?.nbest storefeaturefile=output/exp.mert/nbest/VECFEA/?.vecfea wordmap=wmaps/wmt13.en.wmap
With the wordmap specified, the output of alilats2splats is in readable form in the target language. Note that the sentence boundary symbols and the combined grammar and language model score appear in the nbest file. The N-best lists have the format
- wordindex1 wordindex2 ... translation_score
The relationship of feature vectors and scores at the hypothesis level is as follows:
- Suppose there are m language models, with weights s_1 ...,s_m .
- These weights are specified by the HiFST parameters
lm.featureweights=s_1,s_2,..,s_m
- These weights are specified by the HiFST parameters
- Suppose there are n dimensional feature vectors for each rule,
- The weights to be applied are specified by the HiFST parameters
grammar.featureweights=w_1,..,w_n
- The weights to be applied are specified by the HiFST parameters
- A feature weight vector is formed as P = [s_1 ... s_m w_1 ... w_n]
- A translation hypothesis e has a feature vector F(e) = [lm_1(e) ... lm_m(e) f_1(e) ... f_n(e)]
- lm_i(e): the i-th language model score for e
- f_j(e): j-th grammar feature (see Section 3.2.1, [deGispert2010])
- The score of translation hypothesis e can be found as S(e) = F(e) . P (dot product)
Each line k in the feature file has the format
- lm_1(e_k) ... lm_m(e_k) f_1(e_k) ... f_n(e_k)
which are the unweighted feature values for the k-th hypothesis, e.g.
> zcat -f output/exp.mert/nbest/VECFEA/1.vecfea.gz | head -n 2 62.5442 10.8672 8.3936 -16.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 16.3076 40.5293 63.1159 12.8613 8.7959 -17.0000 -8.0000 -5.0000 0.0000 -1.0000 0.0000 -7.0000 17.0010 43.9482
and the translation_score in line k is F(e_k) . P
> zcat -f output/exp.mert/nbest/VECFEA/1.nbest.gz | head -n 2 <s> parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.0904 <s> the parliament does not support the amendment , which gives you the freedom of tymoshenko </s> 43.1757
Lattice MERT
This section describes how to:
- generate lattices for use with LMERT [Macherey2008]
- run the HiFST implementations of LMERT for iterative parameter estimation [Waite2012]
This HiFST release includes an implementation of LMERT [Waite2012]. The script HiFST_lmert runs several iterations of lattice generation and parameter estimation using the lmert tool.
> export M=10 # run lmert over 10 sentences; for exposition only. > scripts/HiFST_lmert
This script runs 3 iterations of LMERT, with each iteration consisting of the four steps that follow in the sections below. In our experience, on a X86_64 Linux computer with 4 2.8GHz CPUs and 24GB RAM, each iteration takes ca. 3 hours over the full 1502 sentence tuning set. Output from each iteration is written to files log/log.lmert.[1,2,3,4]. For example,
> tail -n 8 log/log.lmert.? ==> log/log.lmert.1 <== Fri Apr 3 21:04:07 2015: RandomLineSearch.INF:Bleu gain less than threshold. Exiting. Fri Apr 3 21:04:07 2015: RandomLineSearch.INF:Initial Bleu: 0.308047 (0.990986) Fri Apr 3 21:04:07 2015: RandomLineSearch.INF:Final Bleu: 0.326275 (0.996078) Fri Apr 3 21:04:07 2015: RandomLineSearch.INF:Final Lambda: 1 0.804341 0.857127 2.94424 -1.08039 1.31302 41.8783 -6.55013 -5.76312 -0.843428 0.294197 0.300588 Fri Apr 3 21:04:07 2015: main.INF:lmert.O2.bin finished! ==Params Fri Apr 3 21:04:10 BST 2015 1,0.804341,0.857127,2.94424,-1.08039,1.31302,41.8783,-6.55013,-5.76312,-0.843428,0.294197,0.300588 ==> log/log.lmert.2 <== Sat Apr 4 00:12:01 2015: RandomLineSearch.INF:Bleu gain less than threshold. Exiting. Sat Apr 4 00:12:01 2015: RandomLineSearch.INF:Initial Bleu: 0.323506 (0.998028) Sat Apr 4 00:12:01 2015: RandomLineSearch.INF:Final Bleu: 0.326441 (0.999893) Sat Apr 4 00:12:01 2015: RandomLineSearch.INF:Final Lambda: 1 1.05897 0.893133 2.81302 -0.752161 1.2221 35.8963 -6.62349 -4.37219 -0.583849 0.242874 0.194865 Sat Apr 4 00:12:01 2015: main.INF:lmert.O2.bin finished! ==Params Sat Apr 4 00:12:04 BST 2015 1,1.05897,0.893133,2.81302,-0.752161,1.2221,35.8963,-6.62349,-4.37219,-0.583849,0.242874,0.194865 ==> log/log.lmert.3 <== Sat Apr 4 04:55:40 2015: RandomLineSearch.INF:Bleu gain less than threshold. Exiting. Sat Apr 4 04:55:40 2015: RandomLineSearch.INF:Initial Bleu: 0.326105 (0.999734) Sat Apr 4 04:55:40 2015: RandomLineSearch.INF:Final Bleu: 0.327024 (0.999893) Sat Apr 4 04:55:40 2015: RandomLineSearch.INF:Final Lambda: 1 1.05159 0.88871 2.80248 -0.750582 1.22436 30.0357 -5.14523 -2.57261 -0.585201 0.249596 0.196453 Sat Apr 4 04:55:40 2015: main.INF:lmert.O2.bin finished! ==Params Sat Apr 4 04:55:43 BST 2015 1,1.05159,0.88871,2.80248,-0.750582,1.22436,30.0357,-5.14523,-2.57261,-0.585201,0.249596,0.196453
This indicates:
- The initial set of parameters yields a tuning set BLEU score of 0.308047, with brevity penalty 0.990986
- The first iteration of LMERT improves the tuning set BLEU score to 0.32652 over the tuning set lattices generated with the initial parameters.
- Retranslation with the parameters found at iteration 1 yields a tuning set BLEU score of 0.32488, with brevity penalty 0.999654
- The second iteration of LMERT improves the tuning set BLEU score to 0.326884 over the tuning set lattices generated with the parameters from iteration 1
Notes:
- The parameters used to initialise this demo are taken from the baseline system, and so few iterations are needed for LMERT to converge. Even when started from a flat start, LMERT tends to converge in fewer iterations than N-Best MERT.
- The n-gram language model is set by default to
M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.withoptions.mmap. This is a quantized version ofM/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap. Slightly higher tuning set BLEU scores can be gotten with the unquantized LM, although memory use in tuning will be higher. - The script
HiFST_lmertcan be modified to perform LMERT over only the first (e.g.) 100 tuning set sentences. This can be done for debugging / demonstration, in that processing will be much faster, although the estimated parameters will not be as robust.
The operations done by the HiFST_lmert script are described next.
Step 1. Hypotheses for LMERT
Note that this step is also done in MERT (MERT (Features Only)), although the settings here are slightly different.
The following command is run at iteration $it , and will generate lattices for $M files.
- Input:
$it– lmert iteration (1, 2, ...)$M– number of sentences to processRU/RU.tune.idx– tuning set source language sentencesG/rules.shallow.vecfea.gz– translation grammarM/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.union.mmap– target language model- language model and translation grammar feature weights, provided via command line option
- Output
output/exp.lmert/$it/LATS/?.fst.gz– word lattices (WFSAs), determinized and minimizedoutput/exp.lmert/$it/hyps– translation hyps (discarded)
The feature weights are gathered into a single vector, and set via the --featureweights command line option
- The first parameter is the grammar scale factor (in the MERT demo, this is set via
lm.featureweights) - The remaining parameters are weights for the grammar features (in the MERT demo, these are set via
grammar.featureweights)
The initial parameters are
it=1 export M=10 FW=1.0,0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136
HiFST is run in translation mode as
> hifst.${TGTBINMK}.bin --config=configs/CF.lmert.hyps --range=1:$M --featureweights=$FW --target.store=output/exp.lmert/$it/hyps --hifst.lattice.store=output/exp.lmert/$it/LATS/?.fst.gz
Step 2. Guided Translation / Forced Alignment
- Input:
$it– lmert iteration (1, 2, ...)$M– number of sentences to processoutput/exp.lmert/$it/LATS/?.fst.gz– word lattices (WFSAs), determinized and minimized (from Step 1. Hypotheses for LMERT)
- Output:
output/exp.lmert/$it/ALILATS/?.fst.gz– transducers mapping derivations to translations (e.g. Fig. 7, [deGispert2010])output/exp.lmert/$it/hyps– translation hyps (discarded)
HiFST is run in alignment mode. Lattices (from output/exp.lmert/$it/LATS/?.fst.gz) read and transformed into substring acceptors used to constrain the space of alignments
> hifst.${TGTBINMK}.bin --config=configs/CF.lmert.alilats --range=1:$M --referencefilter.load=output/exp.lmert/$it/LATS/?.fst.gz --target.store=output/exp.lmert/$it/hyps --hifst.lattice.store=output/exp.lmert/$it/ALILATS/?.fst.gz
Note the following parameters in the configuration file:
[referencefilter] prunereferenceweight=4 # pruning threshold to be applied to input lattice prior to alignment prunereferenceshortestpath=10000 # extract n-best list from input lattice to use as hypotheses
Reference lattices are read from output/exp.lmert/$it/LATS/?.fst.gz. For each lattice:
- an N-Best list of depth 10000 is extracted using
fstshortestpath - the lattices are pruned with threshold
prunereferenceweight=4 - the pruned lattice is unioned with the N-Best list
- the resulting WFSA is transformed (after removing weights, minimization and determinization) into a substring acceptor to be used in alignment
A simpler approach could be simply to prune the reference lattices. However in practice it can be difficult to find a global pruning threshold that always yields a reference lattice that is big enough, but not too big. Including the n-best list ensures that there will always be a rich set of candidate hypotheses.
Step 3. WFSAs with Unweighted Feature Vectors
- Input:
$it– lmert iteration (1, 2, ...)$M– number of sentences to process- language model and translation grammar feature weights, provided via command line options
output/exp.lmert/$it/ALILATS/?.fst.gz– transducers mapping derivations to translations
- Output:
- output/exp.lmert/$it/VECFEA/?.fst.gz – translation lattices (WFSAs) with unweighted feature vectors
alilats2splats transforms ALILATS alignment lattices to sparse vector weight lattices; see Section 2.3.1, [deGispert2010] for a detailed explanation. A single output WFSA with sparse vector weights is written for each translation. Note that this is different from the MERT case, where two N-best lists of hypotheses and features are written for each translation.
The HiFST alilats2splats command is
> alilats2splats.${TGTBINMK}.bin --config=configs/CF.lmert.vecfea --range=1:$M --featureweights=$FW --sparseweightvectorlattice.loadalilats=output/exp.lmert/$it/ALILATS/?.fst.gz --sparseweightvectorlattice.store=output/exp.lmert/$it/VECFEA/?.fst.gz
Step 4. LMERT
- Input:
$it– lmert iteration (1, 2, ...)$M– number of sentences to processoutput/exp.lmert/$it/VECFEA/?.fst.gz– translation lattices (WFSAs) with unweighted feature vectors (from Step 3. WFSAs with Unweighted Feature Vectors)EN/EN.tune.idx– target language references in integer format
- Output:
output/exp.lmert/params.$it– reestimated feature vector under LMERT with BLEU
lmert runs as follows
> lmert.${TGTBINMK}.bin --config=configs/CF.lmert.lmert --range=1:$M \
--input=output/exp.lmert/$it/VECFEA/?.fst.gz --initial_params=$FW \
--write_params=output/exp.lmert/params.$it
BLEU, References, and De/Tokenization
lmert computes the BLEU score with respect to one or more reference translations. References can be provided either as integer-mapped sequences, or as plain text.
The example earlier in this section uses integer-mapped reference translations:
> head -2 EN/EN.tune.idx
50 135 20 103 245 9445 23899
3 245 10 35 578 7 9445 3 5073 972 1052 564 51 13011 317 312 734 6 3 122 14 16306 6 4448 14 119 3570 5
> lmert.${TGTBINMK}.bin --int_refs=EN/EN.tune.idx --range=1:$M \
--input=output/exp.lmert/1/VECFEA/?.fst.gz --initial_params=$FW --random_seed=17 \
--write_params=tmp/params.1
...
Sat Apr 4 11:35:48 2015: RandomLineSearch.INF:Initial Bleu: 0.244382 (1)
Sat Apr 4 11:35:48 2015: RandomLineSearch.INF:Final Bleu: 0.379273 (1)
Sat Apr 4 11:35:48 2015: RandomLineSearch.INF:Final Lambda: 1 1.23568 0.883693 3.50594 -0.200368 -1.51527 41.5974 -4.49443 -5.2153 4.82334 -0.343277 0.45311
...
An alternative is to use plain-text reference files with the word map; with the same random seed, the results should agree with using integer mapped references:
> head -2 EN/EN.tune
parliament does not support amendment freeing tymoshenko
the amendment that would lead to freeing the imprisoned former prime minister was revoked during second reading of the proposal for mitigation of sentences for economic offences .
> lmert.${TGTBINMK}.bin --word_refs=EN/EN.tune --word_map=wmaps/wmt13.en.wmap --range=1:$M \
--input=output/exp.lmert/1/VECFEA/?.fst.gz --initial_params=$FW --random_seed=17 \
--write_params=tmp/params.1
...
Sat Apr 4 11:39:25 2015: RandomLineSearch.INF:Initial Bleu: 0.244382 (1)
Sat Apr 4 11:39:25 2015: RandomLineSearch.INF:Final Bleu: 0.379273 (1)
Sat Apr 4 11:39:25 2015: RandomLineSearch.INF:Final Lambda: 1 1.23568 0.883693 3.50594 -0.200368 -1.51527 41.5974 -4.49443 -5.2153 4.82334 -0.343277 0.45311
...
It is also possible to including de/tokenization of hypotheses prior to BLEU computation. For example, references are processed such that apostrophes are treated as separate tokens:
> awk 'NR==3' EN/EN.tune > the verdict is not yet final ; the court will hear tymoshenko ' s appeal in december .
As an alternative, a set of references can be created which attach apostrophes to words, and the script used to process the references can be provided to lmert as an external tokenizer:
> echo "s/[ ]*'[ ]*/'/" > tmp/sed.apos
> sed -f tmp/sed.apos EN/EN.tune > tmp/EN.tune.apos
> awk 'NR==3' tmp/EN.tune.apos
the verdict is not yet final ; the court will hear tymoshenko's appeal in december .
> lmert.${TGTBINMK}.bin --word_refs=EN/EN.tune --word_map=wmaps/wmt13.en.wmap --range=1:$M \
--input=output/exp.lmert/1/VECFEA/?.fst.gz --initial_params=$FW --random_seed=17 \
--write_params=tmp/params.1 --external_tokenizer="tee tmp/before | sed -u -f tmp/sed.apos | tee tmp/after"
...
Sat Apr 4 11:41:38 2015: RandomLineSearch.INF:Initial Bleu: 0.24523 (1)
Sat Apr 4 11:41:38 2015: RandomLineSearch.INF:Final Bleu: 0.380598 (1)
Sat Apr 4 11:41:38 2015: RandomLineSearch.INF:Final Lambda: 1 1.23568 0.883693 3.50594 -0.200368 -1.51527 41.5974 -4.49443 -5.2153 4.82334 -0.343277 0.45311
...
The tee command makes it possible to compare hypotheses before and after processing:
> diff tmp/before tmp/after | head -4 9c9 < instead of the dictator 's society is composed of rival clans , will be merged the koran . --- > instead of the dictator's society is composed of rival clans , will be merged the koran .
Lmert optimises the BLEU score over the latter sets of hypotheses. Note that it is possible to use the external_tokenizer with integer references, but the external tokenizer will have to be able to read integer sequences at its input and write integer sequences at its output, i.e. it will have to apply a word map internally.
Tropical Sparse Tuple Semiring
The lattices generated by alilats2splats in output/exp.lmert/1/lats/VECFEA are tropicalsparsetuple vector weight lattices.
> zcat output/exp.lmert/1/VECFEA/1.fst.gz | fstinfo | head -n 2 fst type vector arc type tropicalsparsetuple
The scores in these lattices are unweighted by the feature vector weights, i.e. they are the raw feature scores against which L/MERT finds the optimal parameter vector values. Distances under these unweighted vectors do not agree with the initial translation hypotheses, e.g. the shortest-path does not agree with the best translation:
> unset TUPLEARC_WEIGHT_VECTOR > zcat output/exp.lmert/1/VECFEA/1.fst.gz | fstshortestpath | fsttopsort | fstpush --to_final --push_weights | fstprint -isymbols=wmaps/wmt13.en.wmap Warning: cannot find parameter vector. Defaulting to flat parameters Warning: cannot find parameter vector. Defaulting to flat parameters 0 1 <s> 1 1 2 parliament 50 2 3 not 20 3 4 supports 1463 4 5 amendment 245 5 6 , 4 6 7 gives 1145 7 8 freedom 425 8 9 tymoshenko 23899 9 10 </s> 2 10 0,10,1,63.460289,2,7.08984375,3,10.9941406,4,-13,5,-9,6,-6,9,-1,10,-8,11,13.1025391,12,29.7294922,
The sparse vector weight format is
0,N,idx_1,fea_1,...,idx_N,fea_N
where N is the number of non-zero elements in that weight vector.
To compute semiring costs correctly, the TUPLEARC_WEIGHT_VECTOR environment variable should be set to contain the correct feature vector weight; this should be the same feature vector weight applied in translation in steps 1 and 2:
TUPLEARC_WEIGHT_VECTOR=[s_1 ... s_m w_1 ... w_n]
which in this particular example is
> export TUPLEARC_WEIGHT_VECTOR="1,0.697263,0.396540,2.270819,-0.145200,0.038503,29.518480,-3.411896,-3.732196,0.217455,0.041551,0.060136"
The shortest path found through the vector lattice is then the same hypothesis produced under the initial parameter settings:
> zcat output/exp.lmert/1/VECFEA/1.fst.gz | fstshortestpath | fsttopsort | fstpush --to_final --push_weights | fstprint -isymbols=wmaps/wmt13.en.wmap 0 1 <s> 1 1 2 parliament 50 2 3 supports 1463 3 4 amendment 245 4 5 giving 803 5 6 freedom 425 6 7 tymoshenko 23899 7 8 </s> 2 8 0,10,1,62.1510468,2,10.8671875,3,8.39355469,4,-16,5,-8,6,-5,8,-1,10,-7,11,16.3076172,12,40.5292969,
Note that printstrings can be used to extract n-best lists from the vector lattices, if the TUPLEARC_WEIGHT_VECTOR is correctly set:
> zcat output/exp.lmert/1/VECFEA/1.fst.gz | printstrings.${TGTBINMK}.bin --semiring=tuplearc --nbest=10 --unique -w -m wmaps/wmt13.en.wmap --tuplearc.weights=$TUPLEARC_WEIGHT_VECTOR 2>/dev/null
<s> parliament supports amendment giving freedom tymoshenko </s> 20.7778,7.80957,17.8672,-8,-8,-5,0,0,-1,-7,20.0176,18.2979
<s> parliament supports amendment gives freedom tymoshenko </s> 20.7773,8.48828,20.9248,-8,-8,-4,0,-1,0,-7,14.1162,14.1016
<s> parliament supports amendment giving freedom timoshenko </s> 20.7778,9.70703,17.7393,-8,-8,-5,0,0,-1,-7,22.166,18.2529
<s> parliament supports correction giving freedom tymoshenko </s> 20.7768,9.15527,18.6689,-8,-8,-4,0,0,-1,-7,22.4062,20.7334
<s> parliament supports amendment giving liberty tymoshenko </s> 20.7768,10.2051,18.3838,-8,-8,-5,0,0,-1,-7,22.6582,19.4707
<s> parliament supports amendment gives freedom timoshenko </s> 20.7773,10.1602,21.0596,-8,-8,-4,0,-1,0,-7,16.2646,14.0566
<s> parliament supports amendment enables freedom tymoshenko </s> 20.7768,8.48828,20.0742,-8,-8,-4,0,-1,0,-7,50.2627,17.0137
<s> parliament supports amendment enable freedom tymoshenko </s> 20.7768,8.48828,20.6904,-8,-8,-4,0,-1,0,-7,50.2627,15.3457
<s> parliament not supports amendment giving freedom tymoshenko </s> 29.3873,5.82324,12.8096,-9,-9,-6,0,0,-1,-8,16.1914,17.9443
<s> parliament supports amendment providing freedom tymoshenko </s> 20.7769,8.48828,21.1689,-8,-8,-4,0,-1,0,-7,50.2627,17.3027
These should agree with n-best lists generated directly by alilats2splats (see Step 3. Hypotheses with Unweighted Feature Vectors).
Note that there can be significant numerical differences between computations under the tropical lexicographic semiring vs the tuplearc semiring: printstrings and alilats2splats might not give exactly the same results. In such cases, the alilats2splats result is probably the better choice.
Source Sentence Chopping
Long source sentences make the translation process slow and expensive in memory consumption; see [Allauzen2014] for a discussion of how source sentence length affects computational complexity and memory use by HiFST and HiPDT. There are various strategies for controlling translation complexity; pruning has been discussed (Inadmissible Pruning), and it is also possible to set the maximum span and gap spans allowed in translation so as to control computational complexity. However translation quality can be affected if pruning is too heavy or if span constraints are set too aggressively.
An alternative approach is to 'chop' long sentences into shorter segements which can then be translated separately. If the sentence chopping is done carefully, the impact on the translation quality can be minimized. The benefits to chopping are faster translation that consumes less memory. The potential drawbacks are twofold: chopping can prevent the search procedure from finding good hypothesis under the grammar, and care must be taken to correctly apply the target language model at the sentence level.
We describe two approaches to source sentence chopping:
- Explicit Segmentation: Long source sentences are chopped into smaller segments which are each translated separately. The results are then spliced together, in various ways.
- Grammar-based Sentence Chopping: Chopping can be done by inserting the special chop symbol
0in the source sentence, and then translating with a modified grammar. The chopping grammar is constructed so that translation rules are not applied across the chopping points, thus limiting the space of translation that are generated.
To make the tutorial easy to follow, we will simply chop the Russian source sentences at every comma (,) which has index symbol 3:
> awk 'NR==4' wmaps/wmt13.ru.wmap , 3
Chopping by Explicit Source Sentence Segmentation
The original Russian sentence is chopped into shorter sentences which are to be translated independently, as follows:
# sentence 328 is 51 words long
> awk 'NR==328' RU/RU.tune.idx
1 17914 3004 169868 123860 45 1246 53414 16617 15 6 215 26993 7704 5 142 680 13640 2481 1195794 16 7390 24705 14 3 1676 24844 33 3 24 1759 16617 5 18091 42 4340 140478 31410 5 13214 144114 6 8 12859 30201 2623 8 5 913863 4 2
# chop sentence 328 into separate segments;
# split at the 3 symbol, and introduce sentence start and end symbols,
# so that language model and translation grammar are applied correctly
> awk 'NR==328' RU/RU.tune.idx | sed 's, 3 , 3 2\n1 ,g' > tmp/RU.328.segs
> cat tmp/RU.328.segs
1 17914 3004 169868 123860 45 1246 53414 16617 15 6 215 26993 7704 5 142 680 13640 2481 1195794 16 7390 24705 14 3 2
1 1676 24844 33 3 2
1 24 1759 16617 5 18091 42 4340 140478 31410 5 13214 144114 6 8 12859 30201 2623 8 5 913863 4 2
# run HiFST over all segments
# lattices for each segment are written to tmp/seg.328.?.fst
> hifst.${TGTBINMK}.bin --source.load=tmp/RU.328.segs --target.store=tmp/hyps.328.segs --hifst.lattice.store=tmp/seg.328.?.fst --hifst.prune=9 --hifst.replacefstbyarc.nonterminals=X,V --lm.load=M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.withoptions.mmap --grammar.load=G/rules.shallow.gz
# concatenate lattices for each segment
> fstconcat tmp/seg.328.1.fst tmp/seg.328.2.fst | fstconcat - tmp/seg.328.3.fst > tmp/seg.328.123.fst
# print output strings
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc -m wmaps/wmt13.en.wmap -u -n 3 --input=tmp/seg.328.123.fst -w
...
<s> architectural historian mäder toured more than 200 swimming pools , and now gathered experience in his recently published book badefreuden ( joy of swimming ) , </s> <s> where included , </s> <s> from a public pool in munich and the historic bathing palaces in the black forest and functional concrete buildings " . </s> 313.88,1.68848
<s> architectural historian mäder toured more than 200 swimming pools , and now gathered experience in his recent book badefreuden ( joy of swimming ) , </s> <s> where included , </s> <s> from a public pool in munich and the historic bathing palaces in the black forest and functional concrete buildings " . </s> 314.045,5.41211
<s> architectural historian mäder toured more than 200 swimming pools , and now gathered experience in his recently published book badefreuden ( joy of swimming ) , </s> <s> where entered the </s> <s> from a public pool in munich and the historic bathing palaces in the black forest and functional concrete buildings " . </s> 314.115,-0.470703
...
Simply concatenating the output lattices in this way leads to the substrings </s> <s> in every hypothesis in the concatenated lattice. A transducer can be built to remove these from the output lattice. The transducer must
- keep the initial
1(<s>) - keep the final
2(</s>) - delete every
1 2(</s> <s>) sequence - map every word to itself
The following 3-state transducer will do this
> echo -e "0\t1\t1\t1" > tmp/strip_1_2.txt # keep initial `1`
> echo -e "1\t2\t2\t0\n2\t1\t1\t0" >> tmp/strip_1_2.txt # map `1 2` to `0 0`
> echo -e "1\t3\t2\t2" >> tmp/strip_1_2.txt # keep final `2`
> echo -e "3" >> tmp/strip_1_2.txt
> awk '$2 != 1 && $2 != 2 {printf "1\t1\t%d\t%d\n", $2,$2}' wmaps/wmt13.en.wmap >> tmp/strip_1_2.txt
> echo -e "1\t1\t999999998\t999999998" >> tmp/strip_1_2.txt # OOV symbol
> fstcompile --arc_type=tropical_LT_tropical tmp/strip_1_2.txt | fstarcsort > tmp/strip_1_2.fst
# apply the strip_1_2.fst transducer to the fst of the concatenated translation lattices
> fstcompose tmp/seg.328.123.fst tmp/strip_1_2.fst | fstproject --project_output | fstrmepsilon > tmp/seg.328.no12.fst
# look at output
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc -m wmaps/wmt13.en.wmap -w --input=tmp/seg.328.no12.fst
<s> architectural historian mäder toured more than 200 swimming pools , and now gathered experience in his recently published book badefreuden ( joy of swimming ) , where included , from a public pool in munich and the historic bathing palaces in the black forest and functional concrete buildings " . </s> 313.879,1.68848
The top hypothesis, and its score, are unchanged by removing the </s> <s> substrings. Note however that the language model score for this hypothesis are not correct, since the language model histories are not applied correctly at the segment boundaries.
To fix this, the applylm tool (see Language Model Rescoring) can be used to remove and reapply the language model so that it spans the source segment translations. The following example simply removes the language model scores from output/exp.chopping.explicit/LATS/sent_no12.fst and then reapplies them via composition
> applylm.${TGTBINMK}.bin --lm.load=M/interp.4g.arpa.newstest2012.tune.corenlp.ru.idx.withoptions.mmap --lm.featureweights=1 --lm.wps=0.0 --semiring=lexstdarc --lattice.load=tmp/seg.328.no12.fst --lattice.store=tmp/seg.328.no12.relm.fst --lattice.load.deletelmcost
The rescored output is written to tmp/seg.328.no12.relm.fst with correctly applied language model scores, i.e. the LM history is no longer broken by any </s> <s> in the lattice. The total translation cost is much lower (better) than when segment hypotheses are simply combined (i.e. 291.958 vs. 313.879):
> printstrings.${TGTBINMK}.bin --input=tmp/seg.328.no12.relm.fst --semiring=lexstdarc -m wmaps/wmt13.en.wmap -w
<s> architectural historian mäder toured more than 200 swimming pools , and now gathered experience in his recently published book badefreuden ( joy of swimming ) , which included everything from a public pool in munich and the historic bathing palaces in the black forest and functional concrete buildings " . </s> 291.958,-0.329102
Grammar-based Sentence Chopping
Chopping can also be done by inserting a special 'chop' symbol 0 in the source sentence, and then translating with a modified grammar. The chopping grammar is constructed so that translation rules are not applied across the chopping points, thus limiting the space of translation that are generated. Conceptually, translation proceeds as:
- the translation grammar is applied separately to source sentence segments demarcated by chop symbols
- local pruning can be applied to the translations of these segments
- the resulting WFSAs containing translations of the segments are concatenated under the chopping grammar, possibly with local pruning
- the language model is applied to the concatenated WFSA
- top-level, admissible pruning is done under the combined grammar and language model scores
In this way the FSTs produced by translating the segments are concatenated prior to application of the target language model, and the language model context is not broken by the source sentence chopping. As an example, a grammar modified for chopping contains the following rules (without weights):
R 1 1 R R_D_X R_D_X R R_X R_X T 0 0 T T_D_X T_D_X T T_X T_X S S_U S_U S Q Q Q R R U T T
The rules in the first block above are similar to those used in the usual Hiero grammar, with the original 'S' changed to 'R'. These rules are responsible for concatenating the partial translations of the source sentence, starting from the sentence-start symbol '1', up to but not including the first instance of the chopping symbol '0'.
Each subsequent sequence of source words starting with symbol '0', is handled in a similar way by the second block of rules above. Note that the only rule that can be applied to the input symbol '0' is 'T 0 0', making the translation of each chopped segment independent. This makes use of the OpenFST convention of mapping 0 to epsilon: the 0's in the input are parsed as regular symbols by HiFST, while 0's on the output side are mapped to epsilons and ignored in composition with the language model.
The third block of rules above will join together the results obtained for each chopped segment. As with the glue rule 'S' in the usual Hiero grammar, it is necessary to allow this new set of rules to be applied to any span. This is done by setting
cykparser.ntexceptionsmaxspan=S,Q,R,T,U
The additional mapping provided by the last two rules controls the pruning applied to the top CYK cell relative to each chopped segment:
hifst.localprune.conditions=Q,1,100,12,U,1,100,12,X,5,10000,9,V,3,20000,9
In the above example tighter parameters are chosen for 'Q' and 'U' to force pruning. In this way the final lattice obtained by concatenation is prevented from growing too large. However a wider beam (12) with respect to the other cell types is used, to avoid discarding too many potentially useful hypotheses.
It is possible to specify explicitly that FSTs generated for rules with LHS 'X' or 'V' can be kept as pointers rather then expanded in the FST (RTN) that is built for a higher CYK cell. This is achieved setting
hifst.replacefstbyarc=X,V hifst.replacefstbyarc.exceptions=S,R,T
The second line above prevents substitution for rules with LHS 'S', 'R' and 'T'. It is better to have a fully expanded FST for these rules for more effective optimisation (Determinization and Minimisation).
Converting Grammars and Input Text for Chopping
The usual Hiero grammar can be converted for chopping, as follows; note that no-cost, 0 valued, weights are added to rules :
First, create the chopping and glue rules:
> (echo "T T_D_X T_D_X 0" ; echo "T T_X T_X 0" ; echo "T 0 0 0") > tmp/rules.shallow.chop > (echo "S S_U S_U 0" ; echo "U T T 0" ; echo "Q R R 0" ; echo "S Q Q 0") >> tmp/rules.shallow.chop > cat tmp/rules.shallow.chop T T_D_X T_D_X 0 T T_X T_X 0 T 0 0 0 S S_U S_U 0 U T T 0 Q R R 0 S Q Q 0
Next, append all rules, mapping glue rules with LHS S to LHS R:
> zcat G/rules.shallow.gz | sed 's,S,R,g' >> tmp/rules.shallow.chop > gzip tmp/rules.shallow.chop
The source text (RU/RU.set1.chop.idx) will be chopped simply inserting the chopping marker '0' after each comma (integer mapped to 3 in the Russian wordmap); this is a simplistic approach that is easily implemented for this demonstration. We will select sentences with more than 80 words from the source language set:
# there are 3 source sentences longer than 80 words
> awk 'NF > 80 {print $0}' RU/RU.tune.idx > tmp/RU.long.idx
# make a version with the chopping symbol 0 after every comma
> sed 's, 3 , 3 0 ,g' tmp/RU.long.idx > tmp/RU.long.csym.idx
# print the first line; the <epsilon> indicates where the chopping symbol has been inserted
> farcompilestrings --entry_type=line tmp/RU.long.csym.idx | farprintstrings --symbols=wmaps/wmt13.ru.wmap | head -1
<s> спад экономической активности вызвал , <epsilon> до ноября , <epsilon> постоянный рост безработицы в штате , <epsilon> по данным национального института статистики и географии , <epsilon> в течение первых трех кварталов был зафиксирован ускоренный рост уровня безработицы , <epsilon> с января по март 55.053 жителя синалоа были безработными , <epsilon> с долей 4.53 процента экономически активного населения , <epsilon> во втором квартале доля возросла до 5.28 процента , <epsilon> а с июля по сентябрь она продолжила расти до 6.19 процента , <epsilon> доли , <epsilon> которая в пересчете на количество людей составляет более чем 74.000 безработных жителей синалоа , <epsilon> что на 18.969 человек больше по сравнению с первой половиной . </s>
# Run HiFST, without chopping. Input is the original source: tmp/RU.long.idx
# hypotheses are written to output/exp.chopping/nochop/hyps and lattices to output/exp.chopping/nochop/LATS/
# configuration is otherwise
> (time hifst.$TGTBINMK.bin --source.load=tmp/RU.long.idx --target.store=tmp/hyps.long.nochop --hifst.lattice.store=tmp/long.nochop.?.fst.gz --config=configs/CF.baseline ) &> log/log.long.nochop
The decoder requires the following settings to use the chopping grammar:
- hifst.replacefstbyarc.exceptions=S,R,T # Specifies glue rule types in the grammar
- cykparser.ntexceptionsmaxspan=S,Q,R,T,U # List of non-terminals not affected by cykparser.hrmaxheight. S should be here
Now run HiFST, with chopping.
# Input is the source with chopping symbols: tmp/RU.long.csym.idx # hypotheses are written to tmp/hyps.long.gchop and lattices to tmp/long.gchop.?.fst.gz > (time hifst.$TGTBINMK.bin --source.load=tmp/RU.long.csym.idx --target.store=tmp/hyps.long.gchop --hifst.lattice.store=tmp/long.gchop.?.fst.gz --config=configs/CF.baseline --grammar.load=tmp/rules.shallow.chop.gz --cykparser.ntexceptionsmaxspan=S,Q,R,T,U --hifst.replacefstbyarc.exceptions=S,R,T) &> log/log.long.gchop
Comparing the two experiments indicates that chopping requires less memory and runs faster (and note that the LM alone requires ~1GB):
Input/Grammar Tot time Max memory -------- -------- ---------- Unchopped 1m 21s 2.6Gb Chopped 39s 1.6Gb
However, chopping restricts the space of translations. Looking at the scores of the best translation hypotheses, chopping the source sentence prevents the decoder from finding the best scoring hypothesis under the grammar; for the third sentence, the hypothesis produced without chopping has a lower (i.e. better) combined cost (471.123) than the hypothesis produced with chopping (474.753):
# best hypothesis for the 1st sentence, without chopping
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --input=tmp/long.nochop.1.fst.gz -w -m wmaps/wmt13.en.wmap
<s> the decline in economic activity caused , until november , the permanent rise in unemployment in the state , according to the national institute of statistics and geography , in the first three quarters was recorded accelerated growth in unemployment , from january to march 55.053 resident sinaloa were unemployed , with the share of per cent of the economically active population , in the second quarter , the share rose to percent from july to september , she continued to rise to percent share , if calculated per number of people is more than unemployed people in sinaloa , the 18.969 people more than in the first half . </s> 471.123,2.46484
# best hypothesis for the 1st sentence, with chopping
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --input=tmp/long.gchop.1.fst.gz -w -m wmaps/wmt13.en.wmap
<s> the decline in economic activity caused , until november , a permanent rise in unemployment in the state , according to the national institute of statistics and geography , in the first three quarters was recorded accelerated growth in unemployment , from january to march 55.053 resident sinaloa were unemployed , with the share of per cent of the economically active population , in the second quarter , the share rose to percent from july to september , she continued to rise to percent stake , which is recalculated the number of people is more than unemployed people in sinaloa , the 18.969 people more than in the first half . </s> 474.753,4.52344
FST-based True Casing
HiFST includes a tool typically used for true casing the output. It relies on two models:
- A true-case integer-mapped language model in ARPA or KenLM format.
- A flower transducer that transduces uncased words to every true case alternative. This model is loaded from a file with the following format per line, one for each uncased word:
Words must be integer-mapped. A file with this model is available:
> head G/tc.unimap 1 1 1.0 2 2 1.0 3 5943350 0.00002 3 0.86370 5943349 0.13628 4 4 1.00000 5 5 1.00000 6 5942623 0.00452 5942624 0.00002 6 0.99546 7 5943397 0.00000 5943398 0.01875 7 0.98121 5943399 0.00004 8 5941239 0.00003 8 0.99494 5941238 0.00502 9 5942238 0.06269 9 0.93729 5942239 0.00002 10 5943348 0.00001 10 0.99498 5943347 0.00501
For example, under this model word 4 (comma ",") transduces to itself with probability 1. The uncased word 3 ("the") has three upper-case alternatives: "the", "THE", and "The", with the following probabilities
P(the | the) = 0.86 P(THE | the) = 0.00002 P(The | the) = 0.13628
To generate these probabilities, you just need counts of truecased words. You can extract these unigrams with SRILM ngram-count tool, and calculate the probability of each particular true-cased form given the aggregated number of lower-cased instances.
These models are provided to the recaser module via the following configuration options
> cat configs/CF.recaser [recaser] lm.load=M/lm.tc.gz unimap.load=G/tc.unimap
The true casing procedure is very similar to that of SRILM disambig tool. In our case this is accomplished with two subsequent compositions, followed by exact pruning. An acceptable performance vs speed/memory trade-off can be achieved e.g. with offline entropy pruning of the language model.
A range of input lattices can be true-cased in the following way with our fst-based disambig tool:
# re-run the baseline
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline
# recase the output lattices
> disambig.${TGTBINMK}.bin configs/CF.recaser --recaser.input=output/exp.baseline/LATS/?.fst.gz --recaser.output=output/exp.baseline/LATS/?.fst.recase.gz --range=1:2 -s lexstdarc
> printstrings.${TGTBINMK}.bin --input=output/exp.baseline/LATS/?.fst.recase.gz --semiring=lexstdarc --label-map=wmaps/wmt13.en.wmap --range=1:2
<s> Republican strategy of resistance to the renewal of obamas election </s>
<s> The leaders of the Republican justified their policies need to deal with the spin on the elections . </s>
Note that both models need to be integer-mapped, hence the external target wordmap (–label-map) must also map true case words.
HiFST can include truecasing as subsequent step following decoding, prior to writing the output hypotheses. For instance:
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline --recaser.lm.load=M/lm.tc.gz --recaser.unimap.load=G/tc.unimap
> farcompilestrings --entry_type=line output/exp.baseline/hyps | farprintstrings --symbols=wmaps/wmt13.en.wmap
<s> Republican strategy of resistance to the renewal of obamas election </s>
<s> The leaders of the Republican justified their policies need to deal with the spin on the elections . </s>
However, the output lattices are left in uncased form:
> printstrings.${TGTBINMK}.bin --semiring=lexstdarc --label-map=wmaps/wmt13.en.wmap --input=output/exp.baseline/LATS/1.fst.gz
<s> republican strategy of resistance to the renewal of obamas election </s>
Client-Server Mode (Experimental)
HiFST can run in server mode.
> hifst.${TGTBINMK}.bin --config=configs/CF.baseline.server &> log/log.server &
> pid=$! # catch the server pid
Note that in this particular configuration, both source and target wordmaps are loaded. Hifst can read tokenized Russian text and produce tokenized English translations (see options --prepro.wordmap.load and --postpro.wordmap.load). Also, to ensure that CYK parser never fails, out of vocabulary (OOV) words must be detected (--ssgrammar.addoovs.enable) and sentence markers (<s>,</s>) have to be added on the fly, as the shallow grammar relies on them (i.e. S 1 1).
With the hifst-client.${TGTBINMK}.bin binary, we can read Russian tokenized text (RU/RU.tune) and submit translation requests to the server. The output is stored in a file specified by the client tool (--target.store).
> sleep 60 # make sure to wait for the server to finish loading, otherwise clients will fail
> hifst-client.${TGTBINMK}.bin --config=configs/CF.baseline.client --range=200:5:300 --target.store=output/exp.clientserver/translation1.txt &> log/log.client1 &
# Connect to localhost, port=1205 and translate a bunch of sentences. Lets do this in background, just for fun
# Note that the localhost setting is in the config file; this can point to another machine, of course
> pid2=$!
> hifst-client.${TGTBINMK}.bin --config=configs/CF.baseline.client --range=1:50,100,1300 --target.store=output/exp.clientserver/translation2.txt &> log/log.client2 &
# In the meantime, we request another 52 translations...
> wait $pid2
> kill -9 $pid
# We are finished -- kill the server
> head -5 output/exp.clientserver/translation2.txt
parliament does not support the amendment , which gives you the freedom of tymoshenko
amendment , which would have led to the release of which is in prison , former prime minister , was rejected during the second reading of the bill to ease penalty for economic offences .
the verdict is not final , the court will consider an appeal of tymoshenko in december .
a proposal to repeal article 365 of the code of criminal procedure , according to which was convicted former prime minister , was supported by the 147 members of parliament .
victory in libya 